这段时间在参与 AI 落地相关工作的过程中,我逐渐形成了一个相对清晰的判断:
不同组织对「AI 产品经理」的理解,往往并不在同一个层级上。
需要说明的是,这并不是对个人能力高低的划分,而是当 AI 项目承担的责任不同 时,产品角色自然发生的变化。
如果从“AI 在组织中承担的责任”这一维度出发,大致可以划分为三个层级。
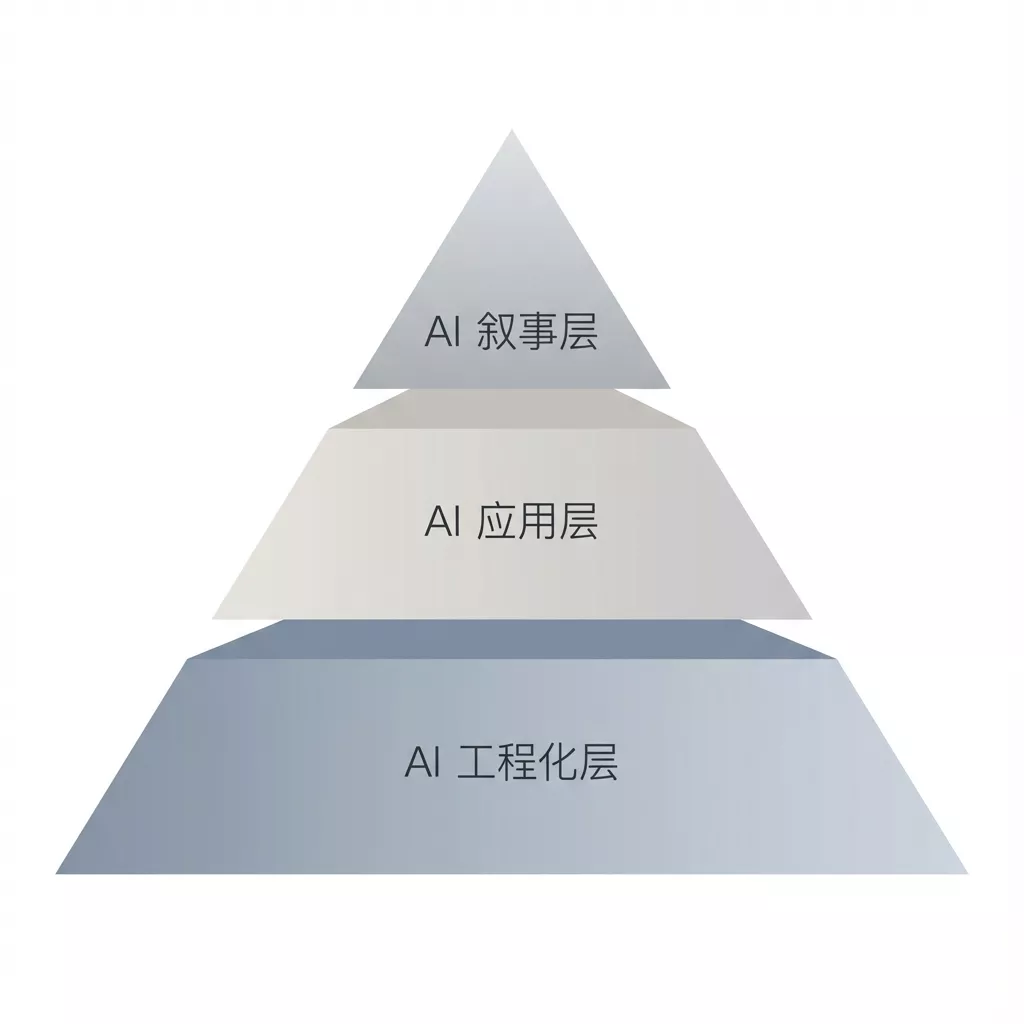
第一层:AI 叙事层
AI 叙事层是大多数组织在引入 AI 时,最先进入、也最容易停留的一层。
这一层的工作,主要围绕“AI 能做什么”展开,包括:
- 描述 AI 可以解决哪些问题
- Demo 能否跑通、是否具备展示效果
- PPT 中的 AI 相关 KPI 是否足够好看
在这个阶段,AI 更多是一种叙事工具,用于解释方向、争取资源、传递信心。
这种推进方式在成熟企业中较为常见,尤其在上市公司环境下更为典型:
- 一方面,风险较低,无需立即承担业务结果的不确定性;
- 另一方面,也更容易为提出者在组织内带来正向增益,例如项目立项、资源倾斜等。
因此,这一层的核心责任在于:方向感与表达能力。
相应的产出,主要体现在方案设计、演示 Demo、以及用于对齐与汇报的 PPT 材料等。
但也正因如此:
这一层并不需要真正的 AI 工程判断介入。
因为一旦引入数据质量、成本、稳定性等现实问题,叙事本身往往就会被打断。
第二层:AI 应用层
当组织不再满足于“讲清楚 AI 能做什么”,而是希望真正把 AI 用起来,就会进入这一层。
这一阶段的典型工作包括:
- 接入模型 API
- 调整提示词、优化单次回复效果
- 设计基础的 Chatbot 交互
- 在小规模场景中验证可行性
相比 AI 叙事层 ,这一层已经开始真正“做事”,也确实能够产出一些可被业务感知的结果。
因此,这一层的核心目标是:可用性与体验成立。
在这一阶段,常见的产出包括 Prompt 提示词、Chatbot 交互原型,以及小规模场景下的效果验证数据。
但很多 AI 产品工作,往往会在这里停住。
原因并不复杂:只要效果还能通过调提示词、换大模型来兜住,工程层面的复杂性就可以被暂时回避。
与此同时,应用层的停滞,往往还源于对 AI 不确定性的错误预期。
我在 Reading Notes #1 中整理过一条 「人工智能时代需要反思的经典产品规则」 ,正是对这一问题的系统性讨论。
需要特别强调的是:AI 应用 ≠ 互联网应用 + 大模型
一个常见但危险的误解,是将 AI 应用简单理解为:
“在原有互联网应用之上,接入大模型能力”。
这种理解之所以容易出现,是因为无论在产品的表层形态,还是在组织实践上,AI 应用都与互联网应用高度相似:
- 在产品层面,同样是 UI 界面、交互流程与 API 调用;
- 在组织实践中,除 AI 模型公司外,最先接入 AI 能力的,往往也正是互联网公司;
- 最终呈现出的结果,就是看起来只是“在原有体系中多接了一个模型”。
但一旦进入需要长期运行、并对业务效果与成本负责的阶段,差异就会迅速显现。
AI 应用真正的分水岭,往往首先出现在 数据 层面——
为大模型准备的数据工程 ≠ 互联网时代的大数据分析
两者在目标、方法与成功标准上,存在本质差异:
- 前者关注的是如何为模型持续提供可用、可控、可演进的数据供给;
- 而后者更多关注的是如何从既有数据中进行统计分析与业务洞察。
从这一差异也可以观察到,AI 应用与互联网应用在运行机制上存在更为本质的不同。
也正因如此,AI 时代并不能简单沿用互联网时代的组织分工方式。
关于这一点,我在 MiniMax 创始人闫俊杰 x 罗永浩
的访谈记录中,也做过一些整理。
而关于互联网思维如何在 AI 时代继续适用,我写过一篇 《从北极星指标出发,分析车主 Chatbot 的现实业务落地》 ,尝试从提升用户互动频次与停留时长这一北极星指标出发,梳理了一版阶段性的产品设计策略,感兴趣的读者可以前往了解。
第三层:AI 工程化层
当目标从“AI 能不能用”,转变为持续优化业务 KPI 时,问题就不可避免地会落到这一层。
一旦公司开始对 AI 应用提出可持续产生业务价值、效果可评估、投入产出可衡量的要求,这些要求本身就会被持续地转译为对模型系统工程的约束:效果能否持续优化、成本能否持续压缩、系统是否支撑高频迭代等。
在这一阶段,关注点会从单次回复效果,转向一系列系统性问题,例如:
- 数据供给是否稳定
- 数据质量是否能够持续控制
- 模型与系统成本如何逐步下降
- 效果能否在真实流量下保持稳定
- 能否复制到第二个、第三个业务场景
这些问题,往往最先体现为工程问题,而工程问题,通常从数据工程开始显现。
我在另一篇文章中记录过一套真实的数据准备与筛选工作流: 关于数据准备的一些经验
在这个阶段,AI 面对的已经不再是“某一次回答准不准”,而是:
是否能够作为一项长期运行的系统能力存在。
因此,这一层的核心责任是:对系统行为与业务结果负责。
相应的产出,也会转向数据管道、效果评测体系、以及围绕成本与稳定性的工程优化。
也正是在这里,工程判断开始成为决定性变量。
一点个人判断
如果一个 AI 项目真的需要对业务结果负责,而不仅仅停留在展示或验证层面:
最终一定会走向工程化层。
只是有的组织走得早,有的组织走得晚,
也有的组织,可能并不打算真正走到这里。
因为这一步,首先并不是技术问题,而是组织能力层面的课题:
- 是否愿意为长期效果承担系统复杂度?
- 是否具备跨数据、工程与业务的协同能力?
- 是否能够围绕真实 KPI 持续投入并承受不确定性?
也正因如此, 组织能力才是 AI 公司真正的壁垒 。
这也解释了,为什么同样叫“AI 产品经理”,
在不同组织中,工作的内容、价值感与发挥空间,会存在显著的差异。